
The skeptic in my head has been saying for years, “How can I measure security efficacy in the real world?” Here’s how.
First, it is important to know that efficacy is measured by calculating the “proportionate reduction in risk.” In the case of COVID-19 vaccines, for example, that occurs when assessing the outcome of applying treatment to one population as compared to an untreated population. That meant monitoring the effect of giving either the real vaccine or a placebo to 30,000 to 40,000 people for each vaccine (population requirements were determined statistically) and assessing the outcomes. With both Pfizer and Moderna, the vaccines resulted in about 95% fewer COVID cases, so that is their efficacy. You can find the efficacy data of all sorts of treatments against all sorts of illnesses and diseases.
In cybersecurity, we have essentially implemented controls based on “best practices” as well as the experiences of professionals. That’s not as bad as it sounds – it’s not witchcraft. We are ultimately evaluating bits and bytes and can capture all of them for analysis. What’s more, we can actively see the traffic and activity that is blocked, unlike in vaccine trials where we are just not sure whether someone is exposed. This means we can use the data in our existing environments to determine efficacy if we make the right assumptions. Namely, we can start with the position that everything blocked is a legitimate negative outcome. (I will discuss how to change this assumption as needed later.)
Measuring email security efficacy
With that in mind, let’s look at the numbers for a standard email security solution, using rounded-off estimates of real-world data. Most organizations today have an initial email filter that blocks obvious spam and malicious messages. In Exchange Online, this is edge protection. Then they go through an email security “car wash” – a series of filters to look for rule violations, malware, DMARC constraints, and anti-spam signature matches. Nowadays, there is even room for a do-over for a post-delivery check.
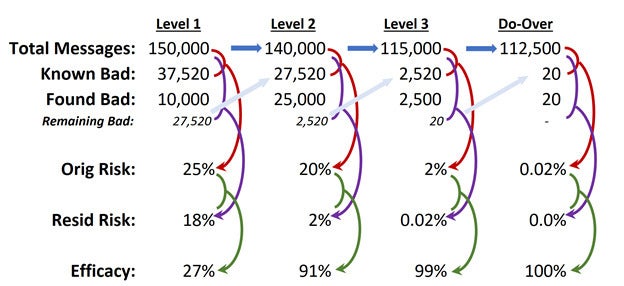
In our simplified example, we start with about 150,000 messages headed toward an organization. Edge protection filters out 10,000 immediately, and then the rules analysis blocks another 25,000. When we get to the car wash (wipers off!), we successfully block another 2,500 messages. Finally, that “zero-hour protection” mulligan blocks another 20. So, we start with 150,000 and end up with 112,480 after losing 37,520 bad messages.
Since we are assuming that everything blocked was done so appropriately, that also means we can calculate what the risk would have been if there were no controls: 37,520/150,000 for about a 25% chance that an email is inappropriate. With this starting point, we can determine email security efficacy at each level of analysis, modifying the calculation slightly to account for the reduction in the message population.
After the first level edge protection is applied, 10,000 messages are blocked and the risk is reduced to about 18% (27,520/150,000), which gives edge protection a 28% efficacy score (the risk level of 25% is reduced by 28% to 18%). This allows 140,000 messages to the next level.
The rules analysis is the real workhorse of the email security solution as it cuts another 25,000 from the 140,000 remaining messages to reduce our risk from about 20% (27,520/140,000 after adjusting the denominator) down to 2% (2,520/140,000) resulting in an efficacy measurement of about 90%.
At the email car wash, we remove another 2,500 messages from the 115,000 remaining, reducing risk from 2% to .02% with an efficacy at 99%. At this stage, the 112,500 messages are delivered, but we have our do-over to catch 20 more “zero-hour” malicious messages, reducing that final .02% of risk to an assumed 0%.
 Peter Lindstrom
Peter LindstromProgression to assess email security efficacy
Dealing with false positives and false negatives
What about those potential false positives and negatives? You can count these and factor them in retroactively as they are identified. Though unnecessary for efficacy measures (and fodder for another column), we can identify false positives by sampling the blocked messages or estimate using references or surveys of “missed emails” that may have been blocked. For false negatives, well, they are adjusted into the numbers upon discovery. Ramp that timeline up through some threat hunting as well.
Armed with these numbers we can, first, rinse and repeat, over and over for a year to get a sense for how the numbers move. Remember, most of these solutions are effective, but from here, we can begin to evaluate alternative solutions. In cybersecurity, it isn’t uncommon to have solutions that can reduce your number of incidents by only a handful or less, making it difficult to determine whether an alternate or additional solution is worthwhile.
Capturing this data and calculating efficacy over time is the only (approaching) objective way we can determine the strength of a security program.
Copyright © 2022 IDG Communications, Inc.