
Whenever I am dealing with cloud services or remote consultants, the one thing that gives me the greatest pause is keeping track of and protecting credentials. Doing so requires multiple backups, cloud resources, and tested backup and recovery processes.
We have our normal password management processes, password storage tools, and encryption processes. Then disaster strikes. Your servers are hit with ransomware or hacked. A device with critical passwords is stolen. A multi-factor authentication device is lost. All these disasters could cause you or someone in your firm to be less than secure in how they handle the transfer and recovery of servers and key operations. How often do you or your consultants test to see if they can handle the recovery process under stress?
Consultant firms often arrange with their clients to stage a disaster and then monitor the results with their staff. Like simulated phishing experiments, these staged disasters are controlled to ensure that data will not be lost and damage to the client is limited to the staged areas. The goal is to ensure that the consulting staff can handle stress during a client’s disaster (albeit a staged event). It’s also to review how they handle processes and procedures, particularly the handling of credentials. Too often in the heat of the moment you find yourself unable to gain access to your normal processes. Ensuring that you handle – and plan for – situations where your normal handling of credentials is disrupted is key to ensuring that you don’t place your firm at greater risk after a disaster.
These are some tips and best practices for recovering credentials after a disaster:
Document server permission changes made during recovery
In the heat of the moment, server permissions are often adjusted to recover them or data and one needs to then document the changes made to ensure that once the incident is over that changes are adjusted. Even when you are done with a security incident, review that you haven’t left your systems in an insecure setting.
Resist taking shortcuts while carrying out established recovery processes
If you have a tested recovery plan, avoid the temptation to go off script to speed the process. As the NIST Guide for Cybersecurity Recovery document indicates:
“Recovery teams should integrate specific recovery procedures based upon the processes used within the organization. Such procedures may include technical actions such as restoring systems from clean backups, rebuilding systems from scratch, enhancing the identity management system and trust boundary, replacing compromised files with clean versions, installing patches, remediating software misconfigurations, securing applications and services, changing passwords, increasing the intensity of monitoring, and tightening network perimeter security (e.g., firewall rulesets, boundary router access control lists). Procedures may also include non-technical actions that involve changes to business processes, human behavior and knowledge, and IT policies and procedures. It is important that the organization take these defined procedures seriously and not purposefully or unknowingly take shortcuts during their execution. Effective recovery will include ongoing use and improvement of both technical and non-technical actions”
Take the time to do root cause analysis
Often a recovery process is different for different sized organizations. A small business might just want to be back functional as soon as possible while a medium-sized business might take the time to do a root cause analysis. According to the NIST document, “Identifying the root cause(s) of a cyber event is important to planning the best response, containment, and recovery actions. While knowing the full root cause is always desirable, adversaries are incentivized to hide their methods, so discovering the full root cause is not always achievable.”
Don’t forget your security settings when you redeploy servers
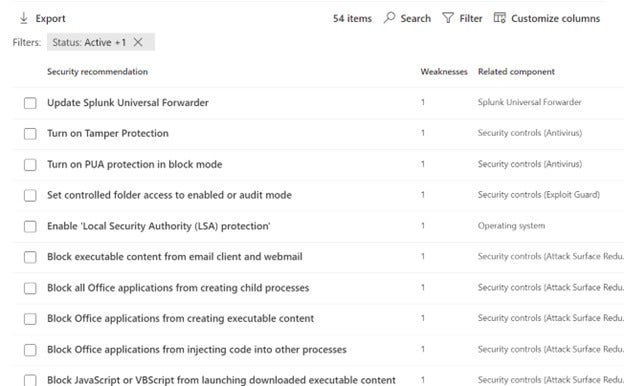
If you use Microsoft Defender for Business Server, Microsoft recommends proactive adjustments to your server to ensure that you can best prevent attacks, specifically that you use the same attack surface reduction rules recommendation for workstations. One example from the screen image below, you want to block all office applications from creating client processes.
 Susan Bradley
Susan BradleyAs you rebuild your network after an incident, remember these settings as you often redeploy servers with default settings. You might not have remembered or documented all your settings that you need to do to better protect your network.
Check your software inventory for potential vulnerabilities
Defender for servers also points out vulnerabilities of third-party software that you may have forgotten is installed on your servers. A software inventory can assist you during incident recovery as well as help prevent a security incident. Knowing exactly what software you have installed on a system helps to identify potential risks to your network.
Admins might forget older software that they no longer use has been left behind on systems and not removed once the project is finished. If you’ve documented the software, the license keys, and deployment customizations, you can more easily restore or rebuild the server back into the same condition. Ideally, you will restore from a backup, but with ransomware, often the attackers find and destroy backup files as well. Know exactly how to recover and rebuild your servers.
Copyright © 2022 IDG Communications, Inc.