
Securing the software supply chain continues to be one of the most discussed topics currently among IT and cybersecurity leaders. A study by In-Q-Tel researchers shows a rapid rise in software supply chain attacks starting around 2016, going from almost none in 2015 to about 1,500 in 2020. The Cloud Native Computing Foundation’s (CNCF’s) catalog of software supply chain attacks also supports a rise in this attack vector.
As software supply chain practices mature, we’ve seen guidance from groups such as the U.S. National Institute of Standards and Technology (NIST), the Open Source Security Foundation (OpenSSF), and now the Center for Internet Security (CIS) with its recently published Software Supply Chain Security Guide. The CIS guide was created in collaboration with Aqua Security, who even made an open-source tool dubbed “chain-bench” to help audit software supply chain stacks for compliance with the guide.
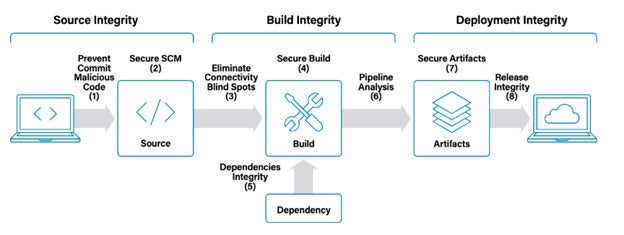
Protecting the five phases of the software supply chain
The intent of the CIS Benchmark for Software Supply Chain Guide is to platform agnostic high-level set of best practices that can subsequently be used to build platform-specific guidance for platforms such as GitHub or GitLab. The guide consists of five core areas:
- Source code
- Build pipelines
- Dependencies
- Artifacts
- Deployment
It also follows the phases of the software supply chain itself from source to deployment and touches on the various potential threat vectors present throughout that process. The image below is reminiscent of another emerging framework, Supply Chain Levels for Software Artifacts (SLSA).
 Center for Internet Security
Center for Internet Security
Collectively the guide covers more than 100 recommendations across the five categories discussed. We will step through each of the five categories highlighting why the area is relevant and some of the guide’s notable recommendations.
Source code
Since the guide follows the software supply chain lifecycle, source code is inevitably at the top of the list given it is the first phase. Source code serves as the source of truth for the remainder of the processes/phases.
You will be looking to secure both the code as well as the source-code management system, which malicious actors can exploit to compromise the source code itself. The guide points out that securing source code involves everything from the developers, sensitive data in the code, and the source-code management platform itself.
The source-code category is broken down into sub-sections that include code changes, repository management, contribution access, third party, and code risks. These sub-sections include critical recommendations. Notable examples under code changes include ensuring code changes are tracked in version control, scanning code merges for risks, and ensuring that code changes require the approval of two strongly authenticated users. Controls such as these ensure that changes are tracked, risks are mitigated prior to allowing code changes and that peer/two-person code reviews from users with appropriate authentication measures occur.
Recommended repository key security controls range from presenting the deletion of issues to specific users, ensuring that public repositories include SECURITY.md files, and cleaning up inactive repositories. These measures help protect the integrity of repositories, guide security or vulnerability feedback, and prevent repository sprawl and lack of governance.
Controlling contribution is another fundamental measure to ensure code integrity. Controls include requiring MFA for code contributions, implementing least-permissive access control to repositories, and limiting Git access to whitelisted IP addresses. Taking these steps improves the security of the code contribution process by limiting source-code access to only those who are authorized, have authenticated appropriately, and are coming from approved IP addresses.
Third-party applications in code repositories pose a risk to organizations. Taking steps such as ensuring an administrator approves installed applications, removing stale applications, and implementing least-permissive control can go a long way. These fundamental controls minimize the organization’s attack surface and limit the blast radius should a third-party application be compromised.
Mitigating code risks is a key activity that organizations must take when dealing with source-code security. Foundational controls such as scanning code for sensitive data or secrets is important, as secret sprawl is a major problem particularly in cloud-native DevOps environments. There’s also the need to scan for vulnerabilities in code via static application security testing (SAST) and practices such as using software composition analysis (SCA) and emerging Software Bill of Materials (SBOM) to look for vulnerabilities in open-source software. components.
Build pipelines
As defined by the CIS guidance, build pipelines are used to take raw files of source code and run a series of tasks to achieve a final artifact as an output. This equates to the latest version of a software/application and is stored and eventually deployed. The build pipeline sub-sections include build environments, build workers, pipeline instructions, and pipeline integrity. The guidance stresses that many of the recommendations are related to self-hosted build platforms, versus software-as-a-service (SaaS) offerings.
The build environment guidance recommends controls such as dedicating pipelines to single repositories, using pipeline infrastructure and configurations that are immutable, and ensuring the activities of the build environment are logged. These controls ensure organizations avoid issues such as drift and configuration deviations, lack of visibility/logging when things go awry and facilitating automation during the creation of the build environments as well. This avoids human errors and issues that can lead to data exposure and misconfigurations that malicious actors can take advantage of.
Build workers, generally called runners, present a core component of the infrastructure for pipeline operations and a target for those seeking to wreak havoc. Workers can check out code, perform testing and even push to the registry, all of which can be used for nefarious purposes. Security controls here include making build workers single-use, segregating duties among the build workers, and implementing runtime security. These activities ensure runtime events are monitored for malicious behavior patterns, limit the attack of a build worker to its assigned duty and minimize the risk of data theft.
Pipeline instructions are used to convert source code into final artifacts. When tampered with, the instructions can be used to perform malicious activities. Security controls include defining build steps as code, defining inputs and outputs clearly, and scanning pipelines automatically for misconfigurations. These controls ensure that the build steps are immutable and repeatable, have anticipated inputs/outputs, and that scans can identify misconfigurations to avoid backdoors or compromises.
Maintaining pipeline integrity is a critical control. This includes the pipeline, necessary dependencies, and the artifacts it produces are as intended to be and unaltered. Key controls in this area include ensuring artifacts are signed upon release, dependencies are validated prior to use, and that the pipeline is producing reproducible artifacts. These controls ensure that artifacts are signed by a trusted entity, dependencies are vetted prior to consumption, and the pipeline is producing artifacts consistently to validate tampering hasn’t occurred. The guidance also recommends not only producing an SBOM for each component of software or build process, but the SBOM itself is also signed to further attest to its validity. These recommendations align with guidance from NIST and OpenSSF and leverage technologies such as Sigstore.
Software dependencies
The guidance recognizes the fundamental role dependencies play in the software supply chain. There is an emphasis on the reality that dependencies generally come from third-party sources and can cause massive damage when exploited, such as Log4j.
Third-party packages require proper governance and use. This includes efforts to establish trust and manage their use appropriately. Third-party packages have the ability to impact not just your software but downstream consumers of your software as well, as was evident with Log4j and its associated flurry of notifications from vendors who’s software was impacted.
Security controls here include verifying third-party artifacts and open-source libraries, requiring SBOM’s from third-party suppliers, requiring and verifying signed metadata of the build process itself. These steps help mitigate the risk of using malicious or high-risk third-party components, understanding what is inside the software of a supplier/vendor and also ensuring artifacts haven’t been compromised during the build process.
The guidance calls for validating packages to understand how and if to use them at all. This includes a combination of policy and technical controls such as establishing organization-wide guidance for dependency use, scanning packages for known vulnerabilities, and maintaining awareness of ownership changes. This helps govern the use of packages while also ensuring existing packages aren’t vulnerable and keeping track of ownership implications that can lead to malicious activity by new owners.
Software artifacts
Artifacts as defined by the guidance are packaged versions of software that become stored in package registries. The guidance stresses the need to secure them throughout the lifecycle from creation all the way to deployment into an environment.
Verification controls are required, such as ensuring artifacts are signed by the pipeline itself, encrypting them before distribution, and controlling who can perform decryption. This ensures the artifacts have integrity, as well as confidentiality, limited to those authorized to view decrypted copies of the artifacts.
Fundamental access controls for artifacts must also be put in place. This often deals with registries that store artifacts and ensuring they aren’t tampered with prior to delivery to a customer through myriad attack vectors. Controls include controlling the number of permitted users who can upload new artifacts, implementing MFA for user access, and separating user management from the package registry to an external authentication mechanism/server.
Package registries represent another component of the attack surface and are where organizational artifacts are stored. While the goal is to protect the artifacts themselves, you can’t do this without also protecting the registries that store them. Controls include auditing configuration changes to the package registry and cryptographic verification for artifacts in the package registry.
Origin traceability or code provenance is another best practice getting increased attention. This means ensuring both the organization and customers understand where an artifact originates from and that it is coming from a trusted source. It is imperative to ensure artifacts have information about their origin, through methods such as SBOMs and metadata. Organizations should also use proxy registries to proxy requests of internal packages from public registries. This recommendation aligns with NIST’s 800-161 Appendix F, which calls for establishing internal registries of known validated components.
Software deployment
Deployment is the final phase of the software supply chain where artifacts ultimately are placed in runtime environments. Controls in this phase include both the deployment configuration and deployment environment.
For the deployment configuration it is recommended to separate deployment configuration files from source code, track deployment configuration changes, and use scanners to secure infrastructure-as-code (IaC) manifests. Misconfigurations or vulnerabilities in deployment configurations can ultimately make the deployment environment vulnerable.
The deployment environment recommendations include making deployments automated and reproducible and limiting access to only those needed. This ensures the deployments are immutable, avoid configuration deviations, and limit access to minimize threats.
While software supply chain security is still an evolving field, this CIS guidance, coupled with guidance from other organizations, serves as a guiding light in a historically shadowy area of cybersecurity. The software supply chain is an incredibly complex and fragile ecosystem that presents system risk due to the countless organizations, consumers, suppliers and industries it impacts. Keep an eye out for subsequent platform specific CIS benchmarks that build on the controls and recommendations cited in the CIS Software Supply Chain Guide.
Copyright © 2022 IDG Communications, Inc.